- Yaqiao Li, Pierre McKenzie, Perspective on complexity measures targeting read-once branching programs, Information and Computation (2024). arXiv:2305.11276.
- Shenggen Zheng, Yaqiao Li, Minghua Pan, Jozef Gruska, Lvzhou Li, Lifting query complexity to time-space complexity for two-way finite automata, Journal of Computer and System Sciences (2024).
- Yaqiao Li, Trading information complexity for error II: the case of a large error and external information complexity, Information and Computation (2022). arXiv:1809.10219.
- Yaqiao Li, Conflict complexity is lower bounded by block sensitivity, Theoretical Computer Science 856 (2021) 169–172. arXiv:1810:08873.
- Yuval Filmus, Hamed Hatami, Yaqiao Li, Suzin You, Information complexity of the AND function in the two-party and multiparty settings, COCOON 2017, Algorithmica vol 81, 4200–4237(2019). arXiv:1703.07833. Here is the Mathematica code used in this paper.
- Yuval Dagan, Yuval Filmus, Hamed Hatami, Yaqiao Li, Trading information complexity for error, CCC 2017, Theory of Computing Vol 14 (2018) Article 6 pp. 1-73. arXiv:1611.06650.
click for a Summary:
Branching program (aka, binary decision diagram) is a more flexible counterpart of decision tree that represents/computes Boolean functions. It is: (i) a basic model for studying computational space, (ii) closely related to pseudorandomness, (iii) a fundamental data structure, (iv) useful to synthesize circuits and in formal verification, etc.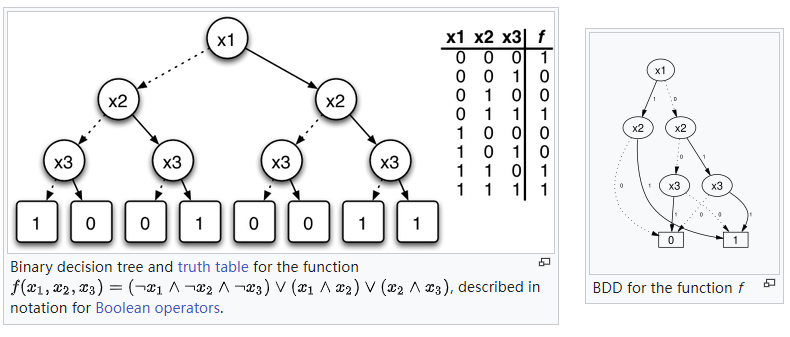
click for a Summary:
Is quantum computing more powerful than classical computing? Recently, many quantum computers built showed superior computational advantage.
click for a Summary:
Information complexity, incorporating Shannon's information theory into communication models, is a continuous version of communication complexity. Initially, it was used to help study communication complexity, and later found many other applications such as in optimization and in circuit complexity, etc.
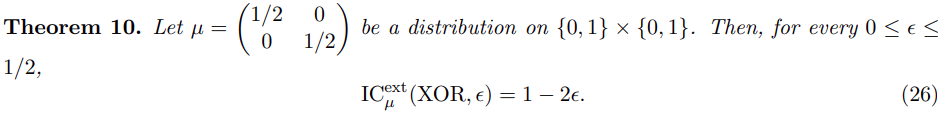
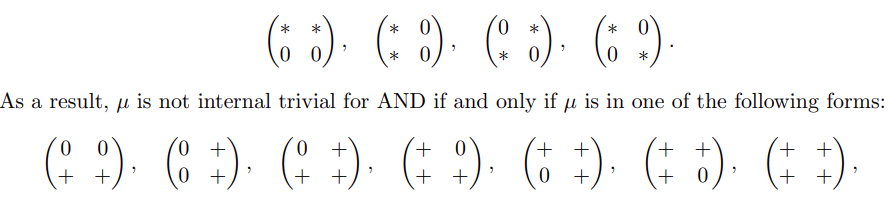
click for a Summary:
If you use a decision tree to compute a composition of two Boolean functions f and g, how does this relate to a decision tree computing f and a decision tree computing g? The measure of conflict complexity was proposed to study (a randomized version of) this problem. Block sensitivity is another complexity measure that tells how a function's value is affected by changing a block of its input.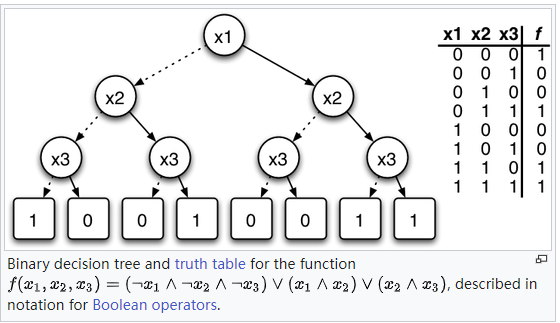
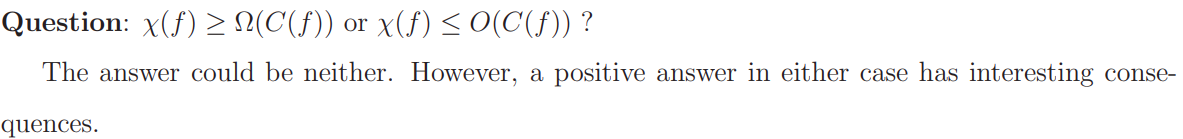
click for a Summary:
Information complexity, incorporating Shannon's information theory into communication models, is a continuous version of communication complexity. Initially, it was used to help study communication complexity, and later found many other applications such as in optimization and in circuit complexity, etc.

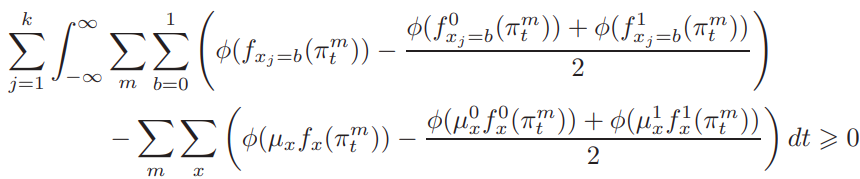
click for a Summary:
Information complexity, incorporating Shannon's information theory into communication models, is a continuous version of communication complexity. Initially, it was used to help study communication complexity, and later found many other applications such as in optimization and in circuit complexity, etc.
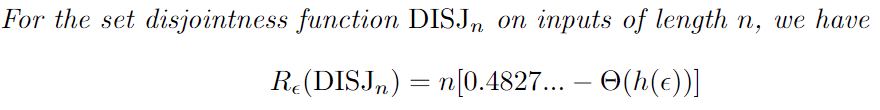

- Yaqiao Li, Ali Mohammad Lavasani, Denis Pankratov, Online interval selection on a simple chain, submitted.
- Yaqiao Li, Mahtab Masoori, Lata Narayanan, Denis Pankratov, Renting servers for multi-parameter jobs in the cloud, ICDCN 2025 (best paper award). ICDCN conference version. arXiv:2404.15444.
- Joan Boyar, Shahin Kamali, Kim S. Larsen, Ali Mohammad Lavasani, Yaqiao Li, Denis Pankratov, On the Online Weighted Non-Crossing Matching Problem, SWAT 2024. SWAT conference version.
- Yaqiao Li, Denis Pankratov, Online Vector Bin Packing and Hypergraph Coloring Illuminated: Simpler Proofs and New Connections, LAGOS 2023, arXiv:2306.11241.
- Yaqiao Li, Vishnu V. Narayan, Denis Pankratov, Online coloring and a new type of adversary for online graph problems, WAOA 2020, Algorithmica (2022). arXiv:2005.10852.
click for a Summary:
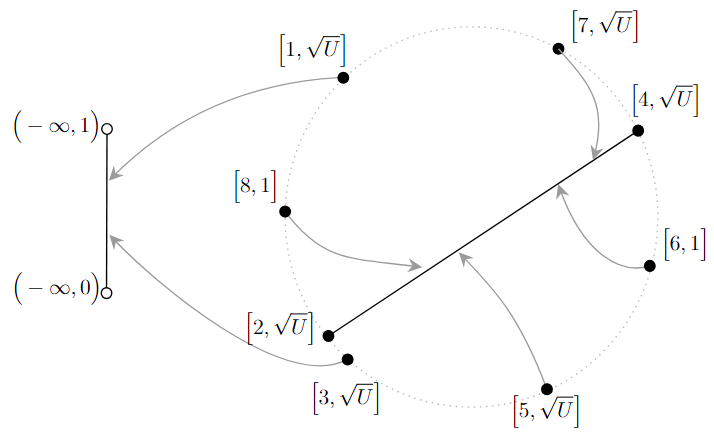
Interval selection models many resource-optimizing scheduling and other conflict-resovling problems. This work shows that a natural revoking algorithm in fact performs worse than the greedy algorithm, when the input intervals form a simple chain and arrive randomly. The solution relies on a clever choice of a partition, and on calculating the resulting infinite series via solving differential equations. We also obtain other bounds, in particular, a first nearly tight bound for advice complexity in this model.A fascinating challenge (we have unsuccessful attempts) is to understand the performance of the revoking algorithm on general interval graphs.
click for a Summary:
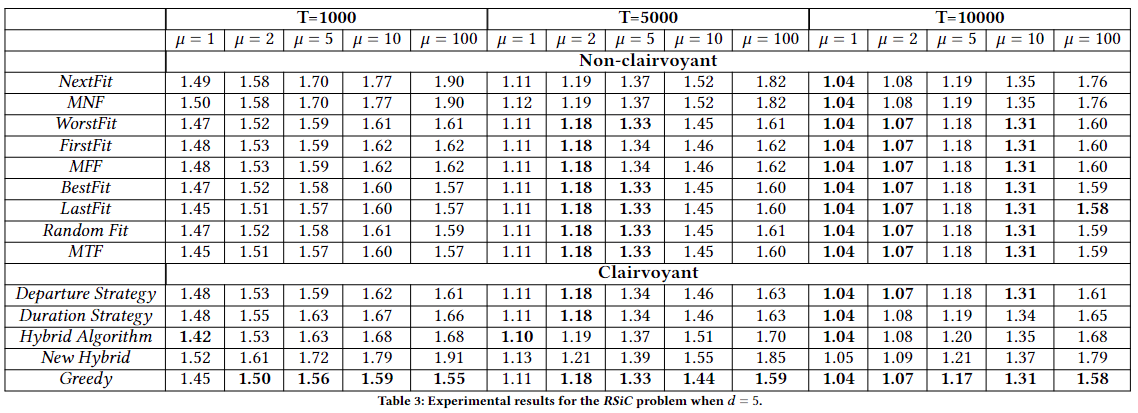
Computing in cloud has many advantages that leads to overall better social welfare, e.g., some companies such as in gaming industry rent servers from public cloud companies for their computational tasks. A basic problem is how to schedule diverse requirements to minimize cost of running cloud servers, this is a dynamic vector bin packing problem called RSiC.

click for a Summary:
Matching is a common task in nature, society, and mathematics. Avoiding crossing (of matching lines/curves) is a desired sometimes indispensable condition, such as for circuit design and understanding RNA structures, etc.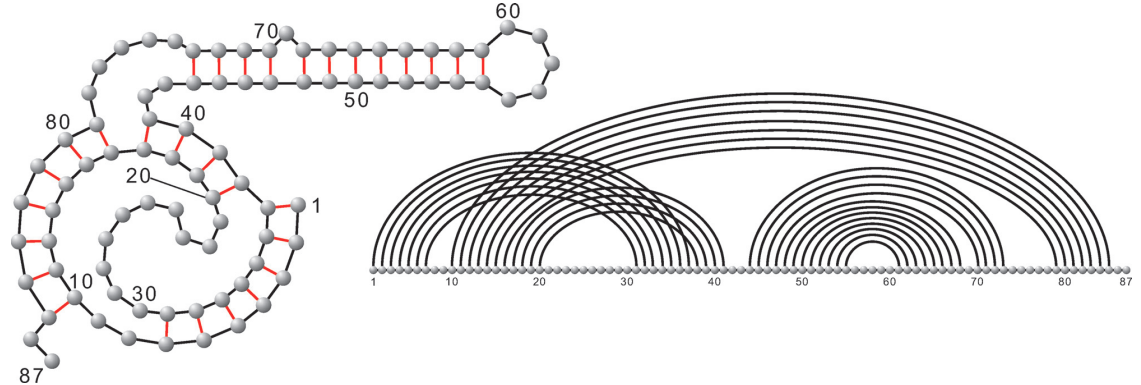
click for a Summary:
Bin packing is a classical NP-complete optimizaiton problem that is also of practical importance such as in loading cargo for shipping, creating file backups in media, etc.
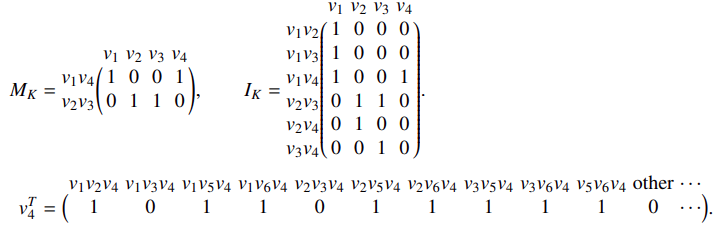
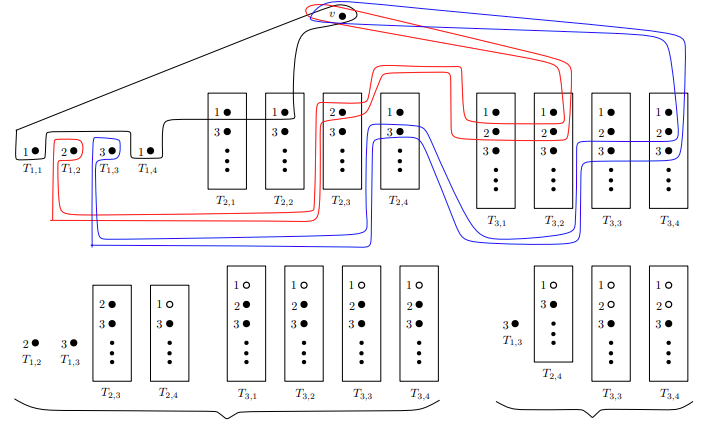
click for a Summary:
Many large networks are constructed online, such as social networks and internet. Such graphs can be modelled by online graph, where at each time step a vertex appears together with its set of edges to some of existing vertices. A fundamental question is: suppose an online graph has completed its construction and turns out to be k-colorable, then, how many colors do we need if we have to irrevocably color every vertex as soon as it appears? A line of work including Lovász et. al. and Gutowski et. al. gives satisfactory understanding for bipartite graphs. For 3-colorable graphs nontrivial progress has also been made, but far from satisfactory.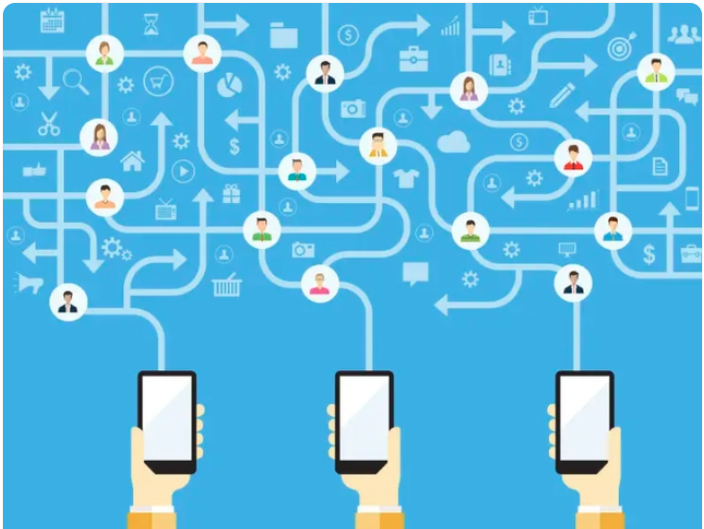

- Yaqiao Li, Ali Mohammad Lavasani, Mehran Shakerinava, Newman's theorem via Carathéodory, arXiv:2406.08500.
- Lianna Hambardzumyan, Yaqiao Li, Chang's lemma via Pinsker's inequality, Discrete Mathematics, vol 343, iss 1 (2020). arXiv:2005.10830
- Hamed Hatami, Pooya Hatami, Yaqiao Li, A characterization of functions with vanishing averages over products of disjoint sets, European J. Combin., vol 56 (2016) 81–93. arXiv:1411.2314.
- Yaqiao Li, The winning property of mixed badly approximable numbers, Moscow J. Comb. Number Theory, vol 3 issue 1 (2013). arXiv:1212.6584.
click for a Summary:
Randomness is useful, sometimes necessary, e.g., you do not want to play a simple deterministic strategy in rock paper scissors. Randomness could help save communication cost as well. Now, if you can share randomness with your communicating partner, versus that you each have private randomness, is there a difference? Newman says they do differ, but not much.


click for a Summary:
This paper, extending the idea in Impagliazzo et.al., gave a short information theoretic proof for Chang's lemma via Pinsker's inequality.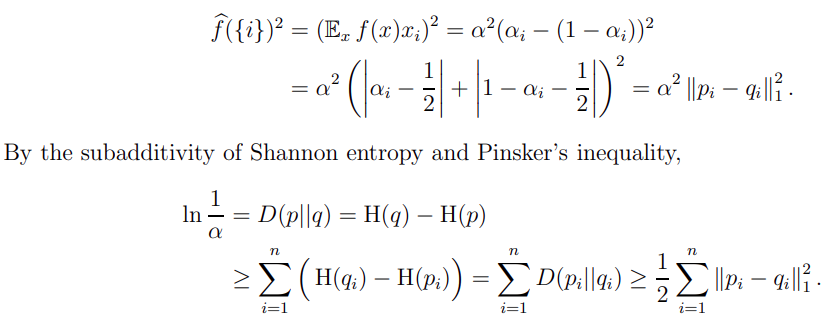
click for a Summary:
Random graph is an important model in mathematics, physics, computer science, and in studying epidemics such as COVID-19. The Erdős–Rényi random graph has its edges generated independently with some probability p. A graph is quasi-random if it has similar statistics of subgraph-counts with the Erdős–Rényi random graph, e.g., the number of triangles should be close to n^3 p^3.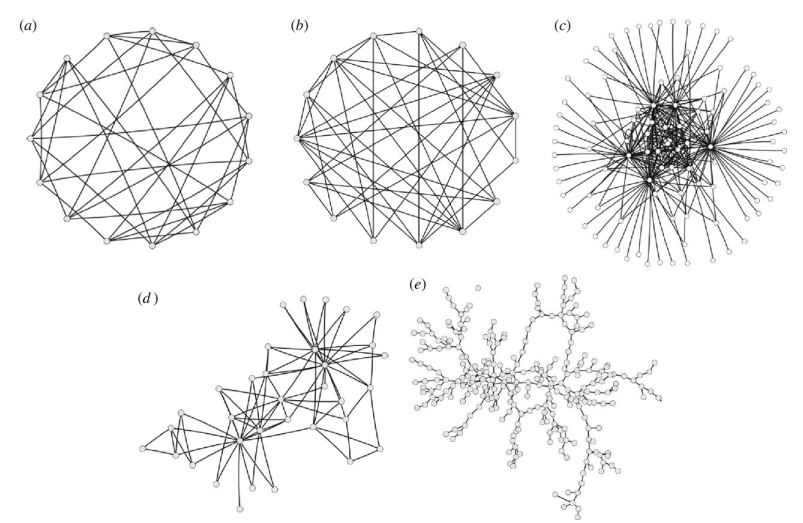
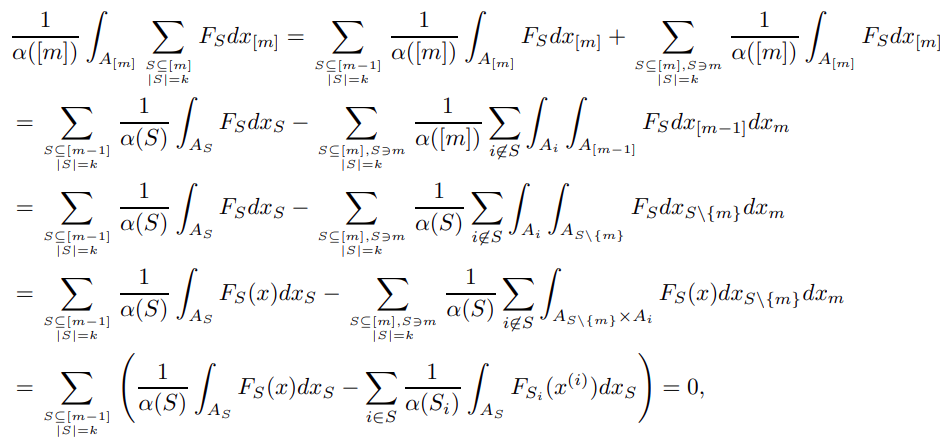
click for a Summary:
This paper improved the winning property of mixed badly approximable numbers to the best possible, thus answered in affirmative a question in a survey of N. Moshchevitin.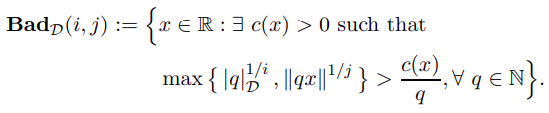
- Yaqiao Li, Lata Narayanan, Jaroslav Opatrny, Yi Tian Xu, Diversity-seeking swap games in networks, AAMAS 2025.
- Dingyu Zhang, Yaqiao Li, Nadia Bhuiyan, A Tale of Two Organizational Structures, pdf.
click for a Summary:
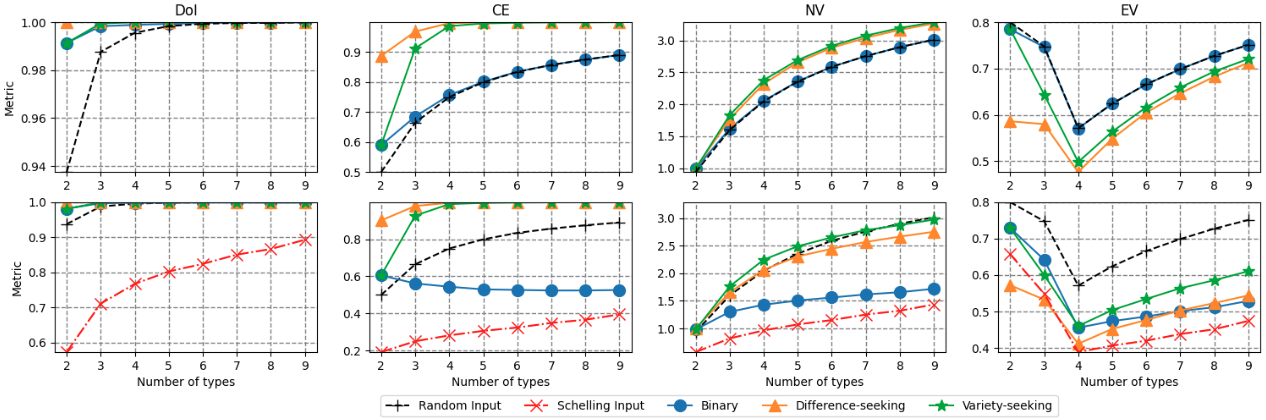
Diversity is observed to be beneficial in social and working environment, and UN calls biodiversity "our strongest natural defense against climate change". Darwin and Wallace already discovered that ecosystem diversity, via niche differentiation, supports higher productivity and better invasion resistance, than a monoculture. Schelling in his original study of segregation of residential neighborhoods (Dynamic models of segregation, 1971) has already, perhaps presciently, experimented diversity-seeking agents (of two types only), called "integrationist", and discovered "phenomena that are not present in the case of purely separatist demands", e.g., "integration requires more complex patterning than separation". Hayes (The Math of Segregation, 2013) observed that "the social fabric of segregation has begun to fray" and "the time has come for a model of racial reintegration".

click for a Summary:
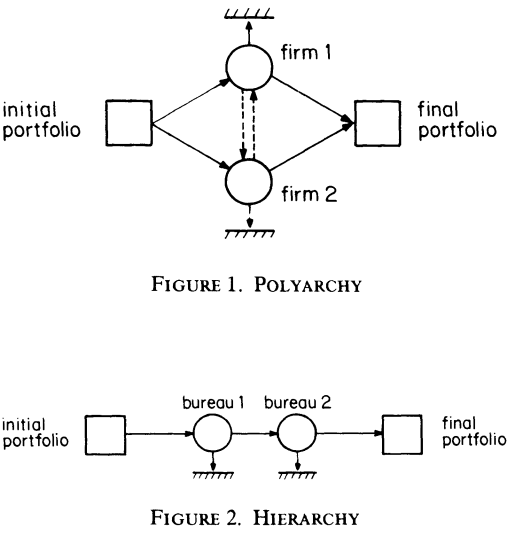
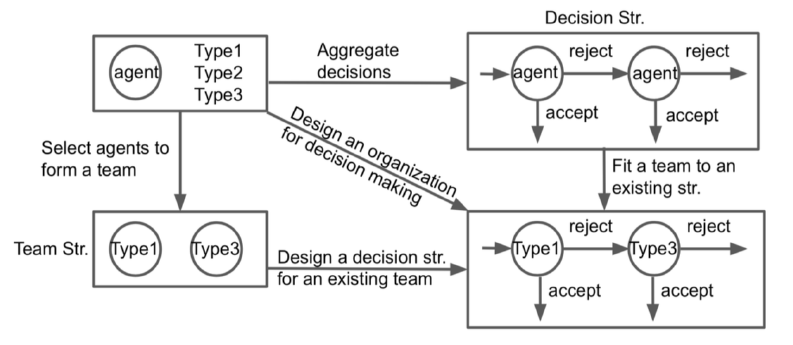
An organization/team consists of diverse people often of distinct capabilities, this we call the team structure. A team makes its decision by aggregating individuals' decisions according to certain pre-speficied rules (e.g., polyarchy, hierarchy, committee, etc) , this we call the decision structure. If an organization has a fixed team, how should it chooses its decision structure? Similarly, if an organization has a fixed decision structure (e.g., cannot be easily changed), what types of people it should hire? More generally, if both sturctures are subject to design (e.g., for a new company), how does an organization systematically consider its various choices?
- Yi Tian Xu, Yaqiao Li, David Meger, Human motion prediction via pattern completion in latent representation space, CRV 2019. arXiv:1904.09039.
click for a Summary:
Knowledge of how humans move can help intelligent robots in tasks involving an interactive human environment, such as navigating through a crowded street, or playing sports or tabletop games with humans.